













 " alt="">
" alt="">


























Data & AI Insights
CorralData
Use AI to effortlessly answer any business questions from all your data.
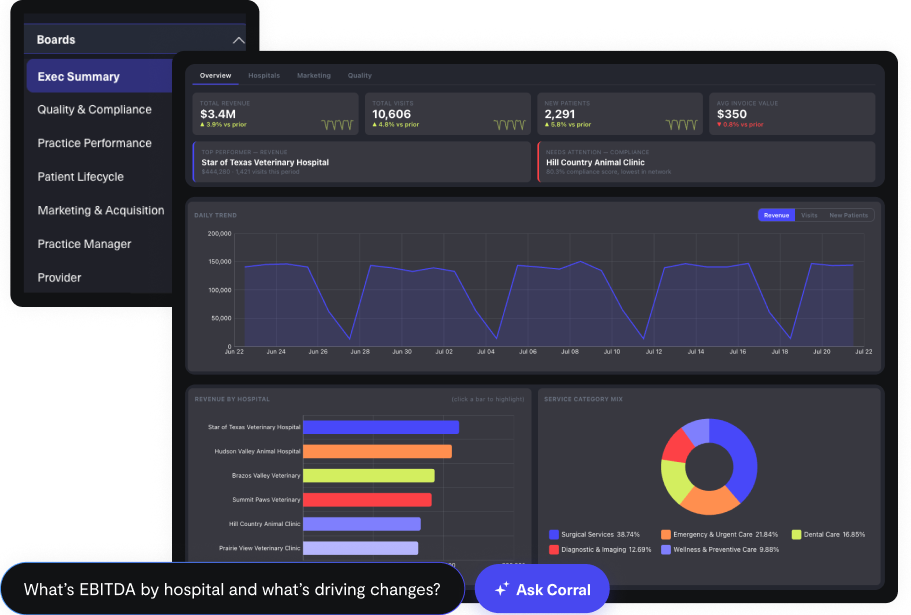
CorralData MCP brings your business data and intelligence directly into Claude and other AI assistants
Build and share custom data applications powered by your connected data.
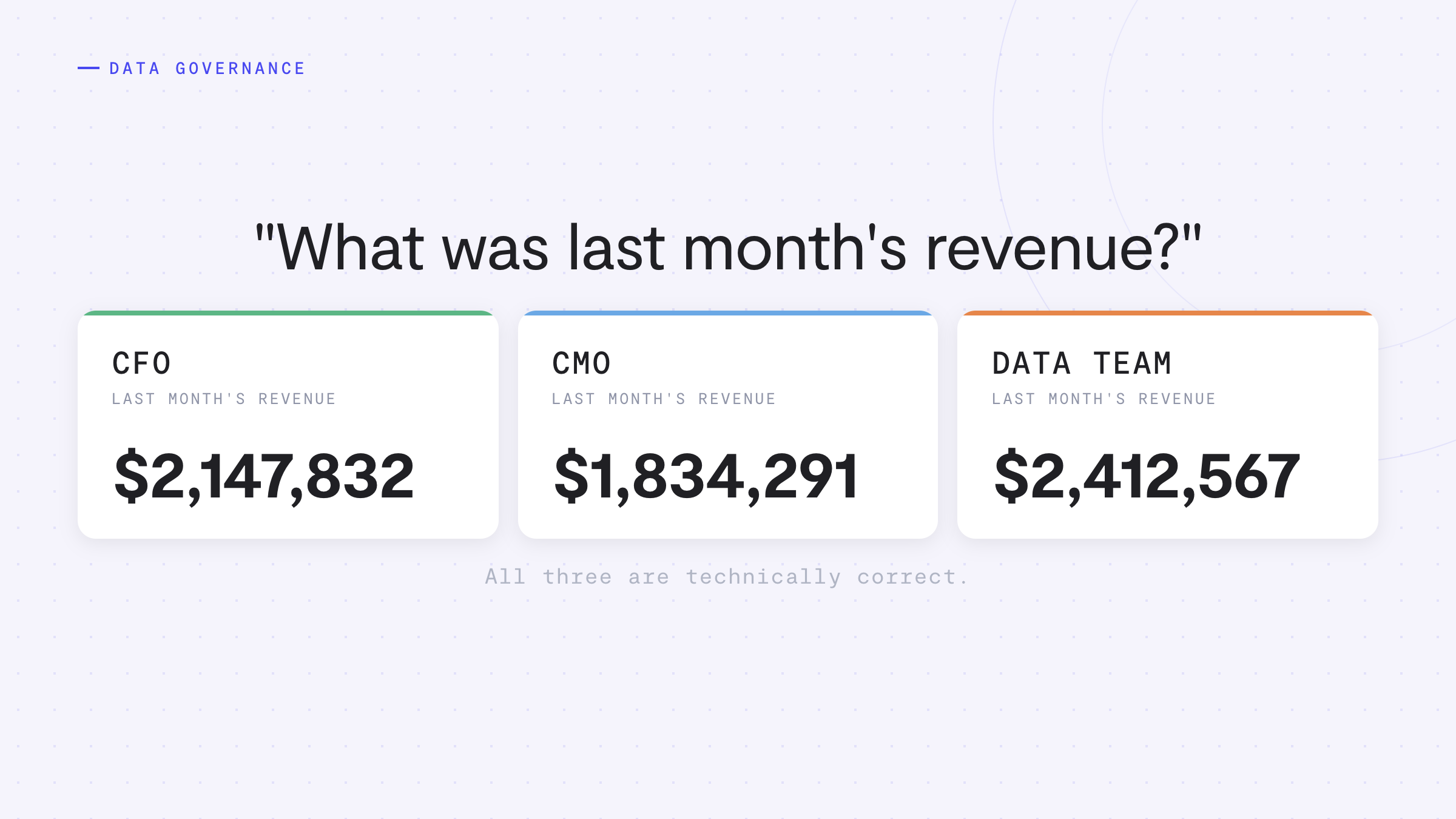
See where accuracy is won or lost across your data stack, and how a governed foundation changes the outcome.
Harness the power of AI without compromising on security.
A dedicated Technical Account Manager guides your team through it
Turn any dashboard into a clear, actionable summary in just one click
AI agents detect opportunities in your data and sync them across your platforms with our fully-managed Reverse ETL.
Sync data from 600+ sources, align KPIs, and see portfolio-wide results instantly.
Help your clients become data driven faster through seamless reporting and collaboration tools.
Grow your census and strengthen your bottom line with HIPAA-compliant analytics.
AI-powered analytics for dental practices and DSOs. Track production, case acceptance, patient recare, and marketing ROI.
Turn data into success with complete visibility of every consumer interaction.
Make data-driven decisions that enhance patient care and your bottom line.
HIPAA-compliant AI agents that optimize operations, marketing, and patient care across every med spa location.
AI-powered analytics for plastic surgery practices. Track consult conversion, surgeon performance, and marketing ROI.
AI agents that monitor, analyze, and optimize performance across every portfolio company.
Easily surface the data you need to increase sales and drive revenue.
Measure every hospital the same way and track compliance across your whole group.
See how AMP scaled profitability and enhanced patient care
See how CorralData & Evolve Results built ADVENT a true ROI engine
See how AMNH gained a better understanding of the ‘why’ behind their data
See how BodyLase unlocked full data visibility, enabling smarter marketing and stronger results
See how evolvetogether used AI-powered insights to shape a unified growth strategy
See how Geode Health unlocked the value of their data while protecting patient privacy
See how Engine identified and converted more high-value customers
See how AI and unified data drove revenue growth at Inspire Aesthetics
See how Lacoste boosted their e-commerce performance with AI-driven insights
See how Moon Juice used live insights to find, reach, and convert their best customers
See how Olympus uses data and AI to fuel growth
See how Options Medical Weight Loss maximized their LTV:CAC
See how Pfizer turned complex data into real-time marketing intelligence
See how Ready Set Rocket streamlined client reporting and unlocked real-time insights
See how Solo Stove measures true channel ROAS with a marketing mix model in CorralData
See how St. John Knits increased marketing efficiency by 50%
See how sweetgreen acquired new customers and built stronger relationships with their most loyal patrons
CorralData
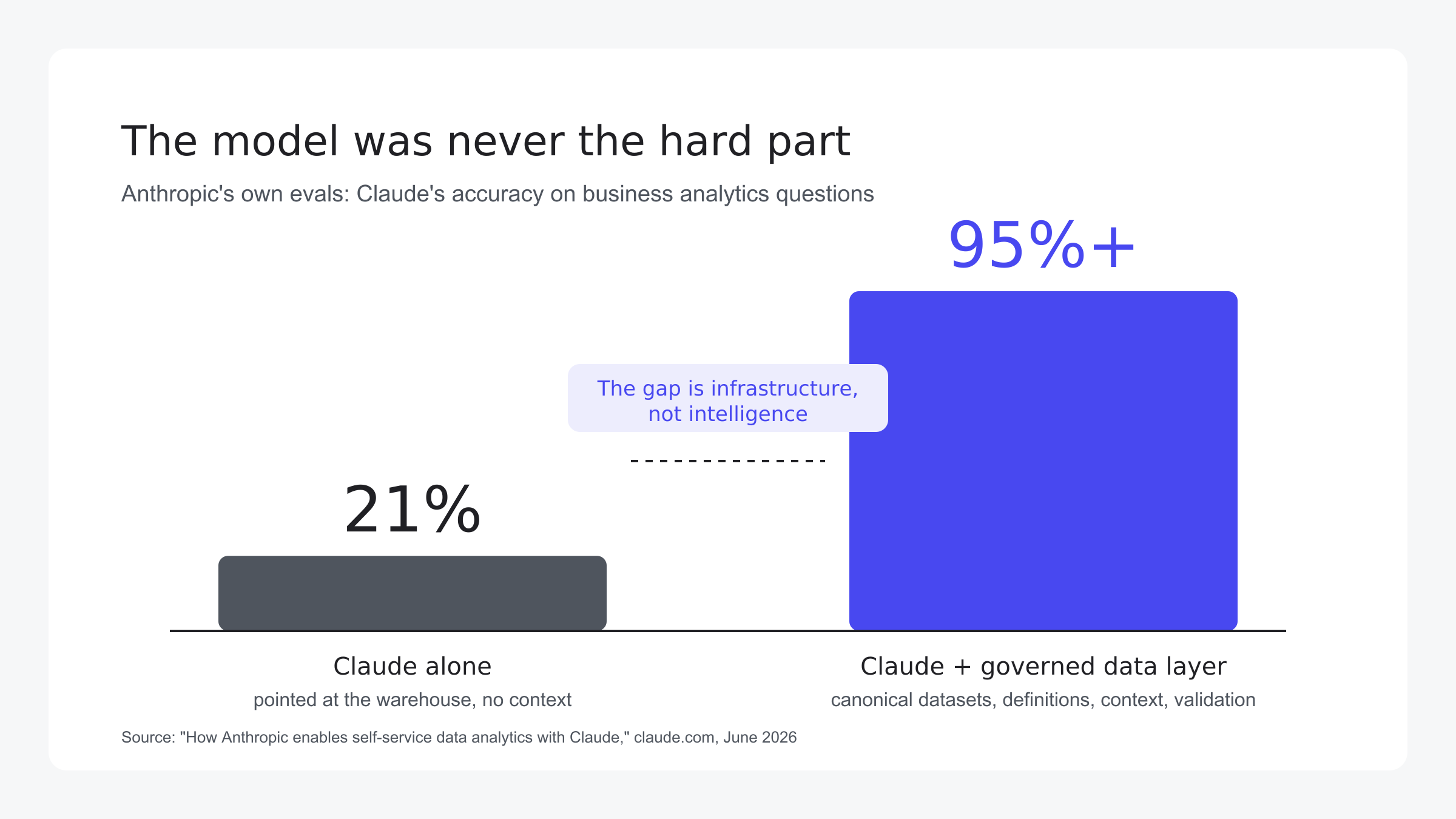
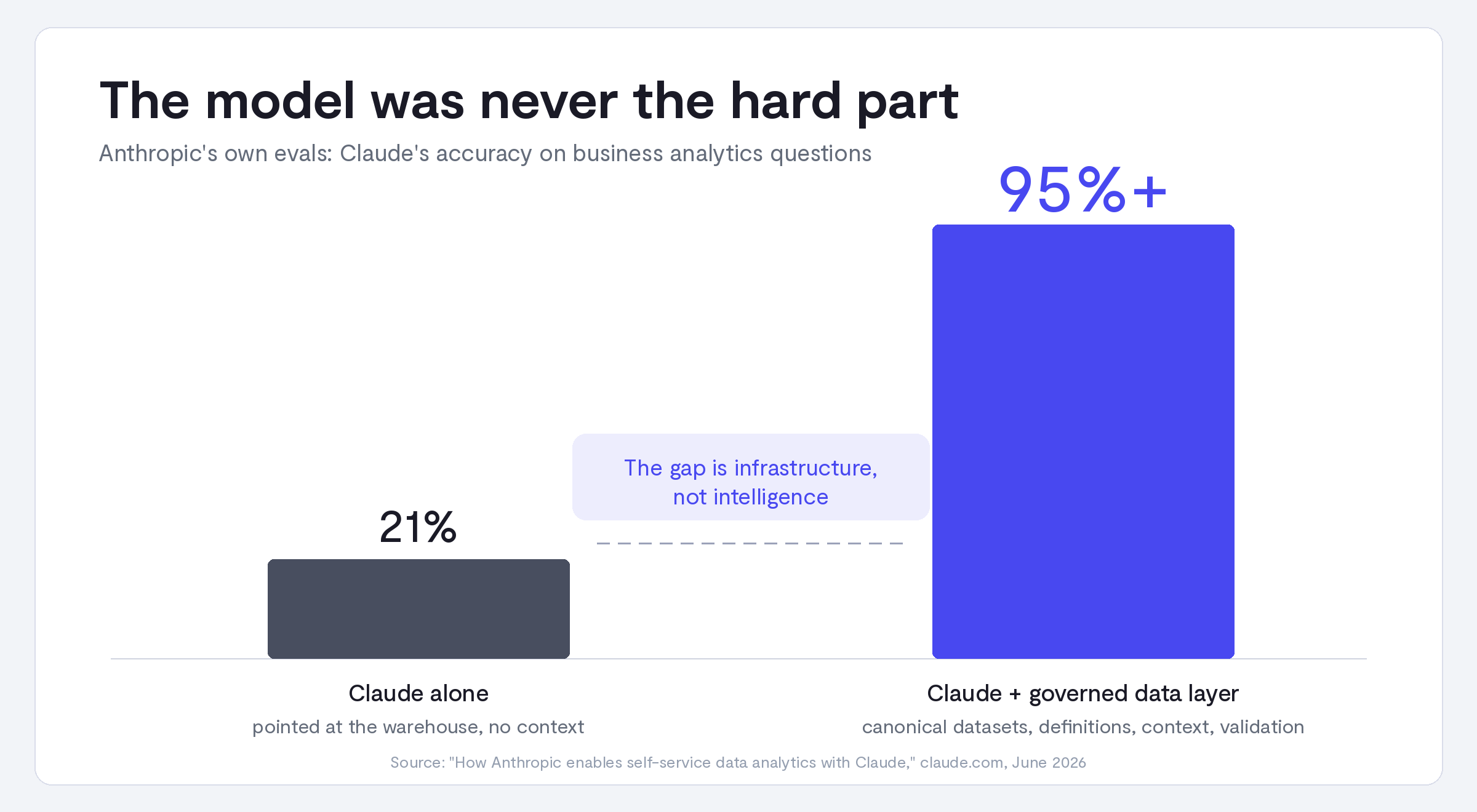
The team behind Claude automated Anthropic’s business analytics queries with 95%+ accuracy. The finding most teams should focus on is a different one: the accuracy was originally just 21%.
In June 2026, Anthropic’s data science and data engineering team published a detailed account of how they enable self-service data analytics with Claude. The headline result is remarkable: 95% of business analytics queries at Anthropic are now automated by Claude, with roughly 95% accuracy in aggregate, freeing their data scientists for forecasting, causal modeling, and machine learning.
If you run a business and you’ve wondered whether your team could just ask an AI questions about your data instead of waiting on dashboards and analysts, this post is the strongest evidence yet that the answer is yes.
But the most important number in the post isn’t 95%. It’s the one Anthropic volunteers about what happened before they built the infrastructure around the model:
That gap, from 21% to 95%, is the entire story. The model was never the hard part. As Anthropic puts it, pointing Claude at a warehouse and letting it run can create “a false sense of precision.” Everything that closed the gap was data infrastructure: governed datasets, curated definitions, maintained context, and validation.
That gap is what CorralData is built to close. This post walks through what Anthropic built, what it takes to replicate, and the shortcut with CorralData.
Anthropic’s framing is one every executive should internalize: analytics accuracy is a context and verification problem, not a code generation problem. Garbage in, garbage out. The model is only as reliable as the context around it. Claude can write flawless SQL. The question is whether it’s querying against the right table, with the right filters, using your company’s actual definition of key metrics, like “revenue.”
Their team identified three failure modes that account for the overwhelming majority of wrong AI answers and why self-serve analytics can fail:

Entity ambiguity. Ask “how many active users do we have?” and the agent faces hundreds of plausible fields. What counts as active? Which lookback window? Include fraudulent accounts? With multiple near-duplicate tables, the agent confidently picks one, and it’s often subtly wrong.
Staleness. Schemas, definitions, and pipelines change constantly. Anthropic reports their own accuracy drifted from roughly 95% at launch to 65% within a month before they treated documentation maintenance as an engineering discipline. Yesterday’s right answer quietly becomes today’s wrong one.
Retrieval failure. Sometimes the right answer exists and is even documented, but across millions of fields the agent simply never finds it. Anthropic ran the experiment: they gave the agent direct access to thousands of historical queries where the correct answer was present about 80% of the time. Accuracy moved by less than a point. Access wasn’t the bottleneck; structure was.
Their solution is a four-layer stack, each layer aimed at one or more failure modes:
Data foundations. Canonical, governed, single-source-of-truth datasets, with the near-duplicates aggressively deprecated. When the agent goes looking for an answer, it finds one — not forty candidates it has to guess between.
Sources of truth. A human-curated semantic layer of metric definitions the agent is structurally required to use first, plus lineage and business context. Notably, they tried having an LLM auto-generate the metric definitions, and it made accuracy worse. Humans own definitions; AI helps with documentation.
Skills. Curated reference docs describing tables, joins, required filters, and gotchas, maintained in the same repo as the data models so every schema change updates the context describing it. This layer alone is what took Anthropic from 21% accuracy to 95%+.
Validation. Checks and balances on the answers the agent returns. Offline eval suites wired into CI, adversarial review of every query (worth +6% accuracy, at the cost of 32% more tokens and 72% higher latency), provenance footers on every answer, and agents that harvest stakeholder corrections into documentation fixes.
Read plainly, here’s what setting up agentic self-service analytics in-house requires: a data engineering team to model and govern the warehouse, a data science team to curate the semantic layer and write evals, CI infrastructure connecting all of it, and a permanent maintenance commitment, because the one time Anthropic relaxed it, accuracy fell from 95% to 65% in a month.
Anthropic’s article explains “what we did” — not “how you do it”. Rebuilding it at your own company means reverse-engineering most of the hard parts, and then staffing the permanent commitment to keep it working.
Anthropic can afford to staff and maintain that. Most growing companies cannot, and shouldn’t have to.
Here’s where most vendor commentary would tell you “don’t try this at home.” We’ll tell you the opposite: do exactly what Anthropic describes. Their architecture is correct. The question is which layers need to be built from scratch.
CorralData exists to be layers one through four, managed for you:

| Layer | Anthropic built | With CorralData |
|---|---|---|
| Data foundations | In-house pipelines, dimensional models, governed canonical datasets, CI enforcement | Managed pipelines from 600+ sources into a governed warehouse with canonical, modeled datasets, built and maintained by our team |
| Sources of truth | Human-curated semantic layer, lineage, business context graph | Your metric definitions, encoded and enforced by us. You own what “revenue” means; we make sure the AI can’t answer with anything else |
| Skills / AI context | Dozens of maintained reference docs, colocated with data models, synced across surfaces | A per-customer context layer describing your tables, joins, filters, and gotchas, updated by us as your data changes |
| Validation | Eval suites in CI, adversarial review agents, correction harvesting, provenance footers | Ongoing accuracy monitoring and query validation by our data team. You sign off on what matters; we catch the drift |
Notice what stays on your side of the table in every row: your definitions and your business context. That’s not a limitation, it’s the design. Anthropic’s own ablation showed that when they let an LLM own the metric definitions, accuracy got worse. The human-owned part of this system is deliberately the part that requires zero engineering: deciding what your metrics mean. You already do that. Everything else, the pipelines, the modeling, the context maintenance, the validation, is the part that requires a team, and that’s the part we run.
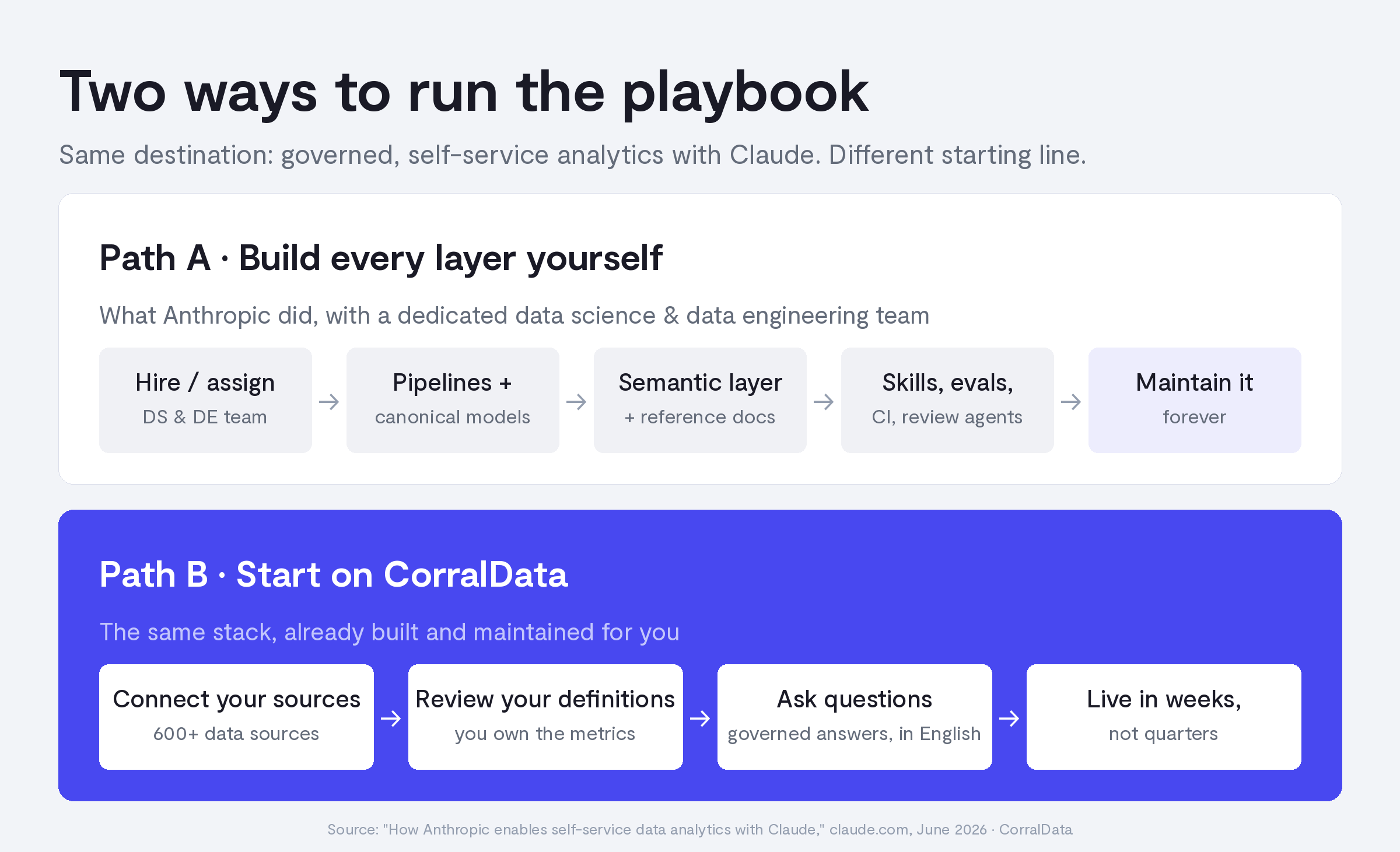
Path A is legitimate. If you have a data engineering and data science team, Anthropic’s post is the best public blueprint available, and their appendix even includes the skill template they use. Budget for the build and, more importantly, for the forever-maintenance: their accuracy decayed 95% to 65% in the single month they under-invested in it.
Path B is the same architecture with the undifferentiated layers delivered as a service. Connect your sources, confirm your metric definitions with our team, and ask questions in plain English, in a governed environment where “revenue” has exactly one answer. Weeks, not quarters. No data hires required.
CorralData comes with AskCorral AI built in. Ask any question about your business and get a governed, accurate answer directly in the platform. For teams that want to do the same in Claude or ChatGPT, the CorralData MCP connector plugs the governed data infrastructure into the model of your choice. That’s the capability Anthropic describes, asking Claude anything about your data and getting answers you can trust.
Anthropic closes with questions every data team should align on, and they double as a buyer’s checklist. Ask any vendor (or your own internal team):
These are the standards we hold ourselves to, and Anthropic’s post is the best argument we’ve seen for demanding them everywhere.
Not reliably. On Anthropic’s own evals, Claude scored 21% accuracy on business analytics questions until it was surrounded by governed datasets, curated definitions, validation, and skills, after which it exceeded 95%.
A four-layer stack: governed data foundations, human-owned sources of truth, maintained AI context (“skills”), and continuous validation. Each layer targets a specific failure mode: ambiguity, staleness, or retrieval failure.
You need the infrastructure that a data engineering team would build, not necessarily the team. CorralData provides the data infrastructure with managed pipelines, governed datasets, AI context, and validation; you keep ownership of metric definitions and business context, which is exactly what Anthropic recommends.
See your own data answering questions in plain English, on governed, canonical datasets, in a live demo with our team.
All figures cited from “How Anthropic enables self-service data analytics with Claude,” claude.com, June 3, 2026. Statistics describe Anthropic’s internal analytics environment and evaluation suite; results in other environments will vary with data complexity and governance maturity.
CorralData


Make your data work for you. Book a demo today to see CorralData in action.


